%\date{} % Activate to display a given date or no date
%\date{} % Activate to display a given date or no date
\begin{document}
\begin{document}
...
@@ -83,7 +86,7 @@
...
@@ -83,7 +86,7 @@
\tableofcontents
\tableofcontents
\begin{abstract}
\begin{abstract}
This document presents the implementations of RL in pseudocode level. First, I present the nomenclature used in these notes. Then I proceed to give my personal views and comments on the motivation behind Selective labels paper. In chapter 2, I define the framework for this problem and give the required definitions. In the following sections, I present the data generating algorithms and algorithms for obtaining failure rates using different methods. Finally in the last section, I present results using multiple different settings.
This document presents the implementations of RL in pseudocode level. First, I present most of the nomenclature used in these notes. Then I proceed to give my personal views and comments on the motivation behind Selective labels paper. In chapter 2, I define the framework for this problem and give the required definitions. In the following sections, I present the data generating algorithms and algorithms for obtaining failure rates using different methods. Finally in the last section, I present results using multiple different settings.
\end{abstract}
\end{abstract}
\section*{Terms and abbreviations}
\section*{Terms and abbreviations}
...
@@ -182,7 +185,7 @@ Given the above framework, the goal is to create an evaluation algorithm that ca
...
@@ -182,7 +185,7 @@ Given the above framework, the goal is to create an evaluation algorithm that ca
\node[state] (EA) [below right=0.75cm and -4cm of MP] {Evaluation algorithm};
\node[state] (EA) [below right=0.75cm and -4cm of MP] {Evaluation algorithm};
@@ -193,6 +196,67 @@ Given the above framework, the goal is to create an evaluation algorithm that ca
...
@@ -193,6 +196,67 @@ Given the above framework, the goal is to create an evaluation algorithm that ca
\label{fig:framework_data_flow}
\label{fig:framework_data_flow}
\end{figure}
\end{figure}
\section{Modular framework -- based on 19 June discussion}
\begin{wrapfigure}{r}{0.25\textwidth}%this figure will be at the right
\centering
\begin{tikzcd}
\arrow[d]&\arrow[d]&\arrow[d]\\
X \arrow[rd]& Z \arrow[d]& W \arrow[ld]\\
& Y &
\end{tikzcd}
\caption{$\M$}
\end{wrapfigure}
\emph{Below is the framework as was written on the whiteboard, then RL presents his own remarks on how he understood this.}
\begin{description}
\item[Data generation:] ~ \\
~ \\
\hskip 3em \textbf{Input:} [none] \\ ~ \\
\textbf{Output:}$X, Z, W, Y$ as specified by $\M$
\item[Decider:] single vs. batch \\
~ \\
\hskip 3em \textbf{Input:}
\begin{itemize}
\item one defendant
\item$\M$
\end{itemize}
\textbf{Output:}
\begin{itemize}
\item argmax likelihood $y$
\item$\pr(Y=0~|~input)$
\item order
\end{itemize}
\item[Evaluator:] ~ \\
~ \\
\hskip 3em \textbf{Input:}
\begin{itemize}
\item Data sample $(X, T, Y)$
\item something about $\M$ and something about Decider(r)
\end{itemize}
\textbf{Output:}
\begin{itemize}
\item$\mathbb{E}[FR~|~input]$
\item curve
\end{itemize}
\end{description}
The above framework is now separated into three different modules: data generation, decider and evaluator. In the first module, all the data points $\{x_i, z_i, w_i, y_i\}$ for all $i=1, \ldots, n$ are created. Outcome $y_i$ is available for all observations.
The next module, namely the decider, assigns decisions for each observation with a given/defined way. This 'decision' can be either the most likely value for y (argmax likelihood y, usually binary 0 or 1), probability of an outcome or an ordering of the defendants.
\textcolor{red}{RL: To do: Clarify the following.}
The evaluator module takes as an input a data sample, some information about the data generation and some information about the decider. The data sample includes features $X, T$ and $Y$ where $Y \in\{0, 1, NA\}$ as specified before. The "something we know about $\M$" might be knowledge on the distribution of some of the variables or their interdependencies. In our example, we know that the $X$ is a standard Gaussian and independent from the other variables. From the decider it is known that its decisions are affected by leniency and private properties X. Next we try to simulate the decision-maker's process within the data sample. But to do this we need to learn the predictive model $\B$ with the restriction that Z can't be observed.
\begin{quote}
\emph{MM:} For example, consider an evaluation process that knows (i.e., is given as input) the decision process and what decisions it took for a few data points. The same evaluation process knows only some of the attributes of those data points -- and therefore it has only partial information about the data generation process. To make the example more specific, consider the case of decision process $\s$ mentioned above, which does not know W -- and consider an evaluation process that knows exactly how $\s$ works and what decisions it took for a few data points, but does not know either W or Z of those data points. This evaluation process outputs the expected value of FR according to the information that's given to it.
\end{quote}
\section{Data generation}
\section{Data generation}
...
@@ -200,7 +264,11 @@ Both of the data generating algorithms are presented in this chapter.
...
@@ -200,7 +264,11 @@ Both of the data generating algorithms are presented in this chapter.
\subsection{Without unobservables (see also algorithm \ref{alg:data_without_Z})}
\subsection{Without unobservables (see also algorithm \ref{alg:data_without_Z})}
In the setting without unobservables Z, we first sample an acceptance rate $r$ for all $M=100$ judges uniformly from a half-open interval $[0.1; 0.9)$. Then we assign 500 unique subjects for each of the judges randomly (50000 in total) and simulate their features X as i.i.d standard Gaussian random variables with zero mean and unit (1) variance. Then, probability for negative outcome is calculated as $$P(Y=0|X=x)=\dfrac{1}{1+\exp(-x)}=\sigma(x).$$ Because $P(Y=1|X=x)=1-P(Y=0|X=x)=1-\sigma(x)$ the outcome variable Y can be sampled from Bernoulli distribution with parameter $1-\sigma(x)$. The data is then sorted for each judge by the probabilities $P(Y=0|X=x)$ in descending order. If the subject is in the top $(1-r)\cdot100\%$ of observations assigned to a judge, the decision variable T is set to zero and otherwise to one.
In the setting without unobservables Z, we first sample an acceptance rate $r$ for all $M=100$ judges uniformly from a half-open interval $[0.1; 0.9)$. Then we assign 500 unique subjects for each of the judges randomly (50000 in total) and simulate their features X as i.i.d standard Gaussian random variables with zero mean and unit (1) variance. Then, probability for negative outcome is calculated as
\begin{equation}
P(Y=0|X=x) = \dfrac{1}{1+\exp(-x)}=\sigma(x).
\end{equation}
Because $P(Y=1|X=x)=1-P(Y=0|X=x)=1-\sigma(x)$ the outcome variable Y can be sampled from Bernoulli distribution with parameter $1-\sigma(x)$. The data is then sorted for each judge by the probabilities $P(Y=0|X=x)$ in descending order. If the subject is in the top $(1-r)\cdot100\%$ of observations assigned to a judge, the decision variable T is set to zero and otherwise to one.
\begin{algorithm}[] % enter the algorithm environment
\begin{algorithm}[] % enter the algorithm environment
\caption{Create data without unobservables}% give the algorithm a caption
\caption{Create data without unobservables}% give the algorithm a caption
...
@@ -223,7 +291,15 @@ In the setting without unobservables Z, we first sample an acceptance rate $r$ f
...
@@ -223,7 +291,15 @@ In the setting without unobservables Z, we first sample an acceptance rate $r$ f
\subsection{With unobservables (see also algorithm \ref{alg:data_with_Z})}
\subsection{With unobservables (see also algorithm \ref{alg:data_with_Z})}
In the setting with unobservables Z, we first sample an acceptance rate r for all $M=100$ judges uniformly from a half-open interval $[0.1; 0.9)$. Then we assign 500 unique subjects (50000 in total) for each of the judges randomly and simulate their features X, Z and W as i.i.d standard Gaussian random variables with zero mean and unit (1) variance. Then, probability for negative outcome is calculated as $$P(Y=0|X=x, Z=z, W=w)=\sigma(\beta_Xx+\beta_Zz+\beta_Ww)$$ where $\beta_X=\beta_Z =1$ and $\beta_W=0.2$. Next, value for result Y is set to 0 if $P(Y =0| X, Z, W)\geq0.5$ and 1 otherwise. The conditional probability for the negative decision (T=0) is defined as $$P(T=0|X=x, Z=z)=\sigma(\beta_Xx+\beta_Zz)+\epsilon$$ where $\epsilon\sim N(0, 0.1)$. Next, the data is sorted for each judge by the probabilities $P(T=0|X, Z)$ in descending order. If the subject is in the top $(1-r)\cdot100\%$ of observations assigned to a judge, the decision variable T is set to zero and otherwise to one.
In the setting with unobservables Z, we first sample an acceptance rate r for all $M=100$ judges uniformly from a half-open interval $[0.1; 0.9)$. Then we assign 500 unique subjects (50000 in total) for each of the judges randomly and simulate their features X, Z and W as i.i.d standard Gaussian random variables with zero mean and unit (1) variance. Then, probability for negative outcome is calculated as
where $\beta_X=\beta_Z =1$ and $\beta_W=0.2$. Next, value for result Y is set to 0 if $P(Y =0| X, Z, W)\geq0.5$ and 1 otherwise. The conditional probability for the negative decision (T=0) is defined as
where $\epsilon\sim N(0, 0.1)$. Next, the data is sorted for each judge by the probabilities $P(T=0|X, Z)$ in descending order. If the subject is in the top $(1-r)\cdot100\%$ of observations assigned to a judge, the decision variable T is set to zero and otherwise to one.
\begin{algorithm}[] % enter the algorithm environment
\begin{algorithm}[] % enter the algorithm environment
\caption{Create data with unobservables}% give the algorithm a caption
\caption{Create data with unobservables}% give the algorithm a caption
...
@@ -262,11 +338,30 @@ The following quantities are computed from the data:
...
@@ -262,11 +338,30 @@ The following quantities are computed from the data:
\item Labeled outcomes: The "traditional"/vanilla estimate of model performance. See algorithm \ref{alg:labeled_outcomes}.
\item Labeled outcomes: The "traditional"/vanilla estimate of model performance. See algorithm \ref{alg:labeled_outcomes}.
\item Human evaluation: The failure rate of human decision-makers who have access to the latent variable Z. Decision-makers with similar values of leniency are binned and treated as one hypothetical decision-maker. See algorithm \ref{alg:human_eval}.
\item Human evaluation: The failure rate of human decision-makers who have access to the latent variable Z. Decision-makers with similar values of leniency are binned and treated as one hypothetical decision-maker. See algorithm \ref{alg:human_eval}.
\item Contraction: See algorithm \ref{alg:contraction} from \cite{lakkaraju17}.
\item Contraction: See algorithm \ref{alg:contraction} from \cite{lakkaraju17}.
\item Causal model: In essence, the empirical performance is calculated over the test set as $$\dfrac{1}{n}\sum_{(x, y)\in D}f(x)\delta(F(x) < r)$$ where $$f(x)= P(Y=0|T=1, X=x)$$ is a logistic regression model (see \ref{sec:model_fitting}, random forest used in section \ref{sec:random_forest}) trained on the labeled data predicting Y from X and $$ F(x_0)=\int_{x\in\mathcal{X}} P(x)\delta(f(x) < f(x_0)) ~ dx.$$ All observations, even ones with missing outcome labels, can be used since empirical performance doesn't depend on them. $P(x)$ is Gaussian pdf from scipy.stats package and it is integrated over interval [-15, 15] with 40000 steps using si.simps function from scipy.integrate which uses Simpson's rule in estimating the value of the integral. (docs: \url{https://docs.scipy.org/doc/scipy/reference/generated/scipy.integrate.simps.html}) See algorithm \ref{alg:causal_model}. \label{causal_cdf}
\item Causal model: In essence, the empirical performance is calculated over the test set as
is a logistic regression model (see section \ref{sec:model_fitting}, random forest used in section \ref{sec:random_forest}) trained on the labeled data predicting Y from X and
All observations, even ones with missing outcome labels, can be used since empirical performance doesn't depend on them. $P(x)$ is Gaussian pdf from scipy.stats package and it is integrated over interval [-15, 15] with 40000 steps using si.simps function from scipy.integrate which uses Simpson's rule in estimating the value of the integral. (docs: \url{https://docs.scipy.org/doc/scipy/reference/generated/scipy.integrate.simps.html}) See also algorithm \ref{alg:causal_model} and motivation from section \ref{sec:motivation} . \label{causal_cdf}
\end{itemize}
\end{itemize}
The plotted curves are constructed using pseudo code presented in algorithm \ref{alg:perf_comp}.
The plotted curves are constructed using pseudo code presented in algorithm \ref{alg:perf_comp}.
\subsection{Short motivation of the causal model presented above:}\label{sec:motivation}
The causal model tries to predict the probability of adverse outcome $Y=0$ when an acceptance rate $r$ is imposed. Estimating such probability in the selective labels setting consists of two parts: predicting the probability for an individual to commit a crime if they are given bail and deciding whether to bail or jail them.
In equations \ref{eq:ep} and \ref{eq:causal_prediction}, $f(x)$ gives the probability given private features $x$. In equation \ref{eq:ep}$\delta(F(x) < r)$ indicates the defendants bail decision. They will be let out if the proportion of people less dangerous than $x_0$ is under $r$. For example, if a defendant $x_0$ arrives in front of a judge with leniency 0.65 they will not be left out if the judge deems that $F(x_0) > 0.65$ that is if the judge thinks that more than 65\% of the defendants are more dangerous than them.
Now the equation \ref{eq:ep} simply calculates the mean of the probabilities forcing the probbility of crime to zero if they will not be given bail.
\begin{algorithm}[] % enter the algorithm environment
\begin{algorithm}[] % enter the algorithm environment
\caption{Performance comparison}% give the algorithm a caption
\caption{Performance comparison}% give the algorithm a caption
...
@@ -374,7 +469,7 @@ The plotted curves are constructed using pseudo code presented in algorithm \ref
...
@@ -374,7 +469,7 @@ The plotted curves are constructed using pseudo code presented in algorithm \ref
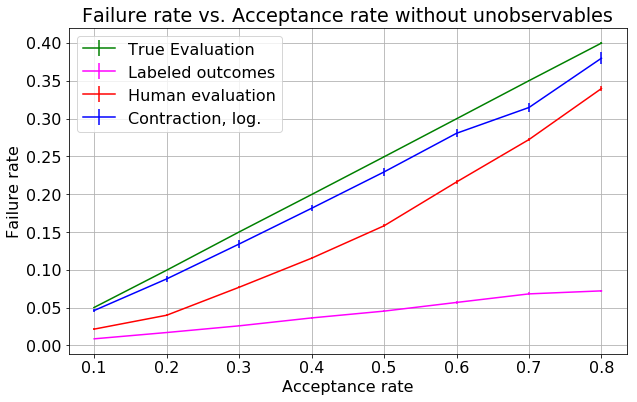
Results obtained from running algorithm \ref{alg:perf_comp} with $N_{iter}$ set to 3 are presented in table \ref{tab:results} and figure \ref{fig:results}. All parameters are in their default values and a logistic regression model is trained.
Results obtained from running algorithm \ref{alg:perf_comp} with $N_{iter}$ set to 3 are presented in table \ref{tab:results} and figure \ref{fig:results}. All parameters are in their default values and a logistic regression model is trained.
\caption{Failure rate vs. acceptance rate with varying levels of leniency. Logistic regression was trained on labeled training data. $N_{iter}$ was set to 3.}\label{fig:results}
\caption{Failure rate vs. acceptance rate with varying levels of leniency. Logistic regression was trained on labeled training data. $N_{iter}$ was set to 3.}\label{fig:results}
\end{figure}
\end{figure}
\subsection{$\beta_Z=0$ and data generated with unobservables.}
\subsection{$\beta_Z=0$ and data generated with unobservables.}
If we assign $\beta_Z=0$, almost all failure rates drop to zero in the interval 0.1, ..., 0.3 but the human evaluation failure rate. Results are presented in Figures \ref{fig:betaZ_1_5} and \ref{fig:betaZ_0}.
If we assign $\beta_Z=0$, almost all failure rates drop to zero in the interval 0.1, ..., 0.3 but the human evaluation failure rate. Results are presented in figures \ref{fig:betaZ_1_5} and \ref{fig:betaZ_0}.
The differences between figures \ref{fig:results_without_Z} and \ref{fig:betaZ_0}could be explained in the slight difference in the data generating process, namely the effect of $W$ or $\epsilon$. The effect of adding $\epsilon$ (noise to the decisions) is further explored in section \ref{sec:epsilon}.
The disparities between figures \ref{fig:results_without_Z} and \ref{fig:betaZ_0}(result without unobservables and with $\beta_Z=0$) can be explained in the slight difference in the data generating process, namely the effect of $\epsilon$. The effect of adding $\epsilon$ (noise to the decisions) is further explored in section \ref{sec:epsilon}.
\caption{Results with unobservables, $\beta_Z$ set to 0 in algorithm \ref{alg:data_with_Z}.}
\caption{Results with unobservables, $\beta_Z$ set to 0 in algorithm \ref{alg:data_with_Z}.}
\label{fig:betaZ_0}
\label{fig:betaZ_0}
...
@@ -435,9 +529,9 @@ The differences between figures \ref{fig:results_without_Z} and \ref{fig:betaZ_0
...
@@ -435,9 +529,9 @@ The differences between figures \ref{fig:results_without_Z} and \ref{fig:betaZ_0
In this part, Gaussian noise with zero mean and 0.1 variance was added to the probabilities $P(Y=0|X=x)$ after sampling Y but before ordering the observations in line 5 of algorithm \ref{alg:data_without_Z}. Results are presented in Figure \ref{fig:sigma_figure}.
In this part, Gaussian noise with zero mean and 0.1 variance was added to the probabilities $P(Y=0|X=x)$ after sampling Y but before ordering the observations in line 5 of algorithm \ref{alg:data_without_Z}. Results are presented in Figure \ref{fig:sigma_figure}.
\caption{Failure rate with varying levels of leniency without unobservables. Noise has been added to the decision probabilities. Logistic regression was trained on labeled training data with $N_{iter}$ set to 3.}
\caption{Failure rate with varying levels of leniency without unobservables. Noise has been added to the decision probabilities. Logistic regression was trained on labeled training data with $N_{iter}$ set to 3.}
\label{fig:sigma_figure}
\label{fig:sigma_figure}
\end{figure}
\end{figure}
...
@@ -448,14 +542,14 @@ In this section the predictive model was switched to random forest classifier to
...
@@ -448,14 +542,14 @@ In this section the predictive model was switched to random forest classifier to
\caption{Predicted class label and probability of $Y=1$ versus X. Prediction was done with a logistic regression model. Colors of the points denote ground truth (yellow = 1, purple = 0). Data set was created with the unobservables.}
\caption{Predicted class label and probability of $Y=1$ versus X. Prediction was done with a logistic regression model. Colors of the points denote ground truth (yellow = 1, purple = 0). Data set was created with the unobservables.}
\label{fig:sanity_check}
\label{fig:sanity_check}
\end{figure}
\end{figure}
...
@@ -481,8 +575,19 @@ Given our framework defined in section \ref{sec:framework}, the results presente
...
@@ -481,8 +575,19 @@ Given our framework defined in section \ref{sec:framework}, the results presente
\caption{Failure rate vs. acceptance rate with different levels of leniency. Data was generated with unobservables and $N_{iter}$ was set to 15. Machine predictions were done with completely random model, that is prediction $P(Y=0|X=x)=0.5$ for all $x$.}
\caption{Failure rate vs. acceptance rate. Data with unobservables and $N_{iter}=15$. Machine predictions with random model.}
\label{fig:random_predictions_with_Z}
\end{subfigure}
\caption{Failure rate vs. acceptance rate with varying levels of leniency. Machine predictions were done with completely random model, that is prediction $P(Y=0|X=x)=0.5$ for all $x$.}

{kind=link}