@@ -31,15 +33,16 @@ This document presents the implementations of RL in pseudocode level. First, I p
\section*{Terms and abbreviations}
\begin{description}
\item[R] acceptance rate, leniency of decision maker, $r \in[0, 1]$
\item[X] personal features, observable to a predictive model
\item[Z] some features of a subject, unobservable to a predictive model, latent variable
\item[W] noise added to result variable Y
\item[T] decision variable, bail/positive decision equal to 1, jail/negative decision equal to 0
\item[Y] result variable, no crime/positive result equal to 1, crime/negative result equal to 0
\item[SL] Selective labels
\item[Labeled data] data that has been censored, i.e. if negative decision is given (T=0), then Y is set to NA.
\item[Unobservables] unmeasured confounders, latent variables, Z
\item[R:] acceptance rate, leniency of decision maker, $r \in[0, 1]$
\item[X:] personal features, observable to a predictive model
\item[Z:] some features of a subject, unobservable to a predictive model, latent variable
\item[W:] noise added to result variable Y
\item[T:] decision variable, bail/positive decision equal to 1, jail/negative decision equal to 0
\item[Y:] result variable, no crime/positive result equal to 1, crime/negative result equal to 0
\item[SL:] Selective labels, see \cite{lakkaraju17}
\item[Labeled data:] data that has been censored, i.e. if negative decision is given (T=0), then Y is set to NA.
\item[Full data:] data that has all labels available, i.e. \emph{even if} negative decision is given (T=0), Y will still be available.
\item[Unobservables:] unmeasured confounders, latent variables, Z
\end{description}
Mnemonic rule for the binary coding: zero bad (crime or jail), one good!
...
...
@@ -48,11 +51,11 @@ Mnemonic rule for the binary coding: zero bad (crime or jail), one good!
\emph{This chapter is to present my comments and insight regarding the topic.}
The motivating idea behind the SL paper of Lakkaraju et al. \cite{lakkaraju17} is to evaluate if machines could improve on human performance. In general case, comparing the performance of human and machine evaluations is simple. In the domains addressed by Lakkaraju et al. simple comparisons would be unethical and therefore algorithms are required. (Some other data augmentation algorithms have been proposed by De-Arteaga \cite{dearteaga18}.)
The motivating idea behind the SL paper of Lakkaraju et al. \cite{lakkaraju17} is to evaluate if machines could improve on human performance. In general case, comparing the performance of human and machine evaluations is simple. In the domains addressed by Lakkaraju et al. simple comparisons would be unethical and therefore algorithms are required. (Other approaches, such as a data augmentation algorithm has been proposed by De-Arteaga \cite{dearteaga18}.)
The general idea of the SL paper is to train some predictive model with selectively labeled data. The question is then "how would this predictive model perform if it was to make independent bail-or-jail decisions?" That quantity can not be calculated from real-life data sets due to the ethical reasons. We can however use more selectively labeled data to estimate it's performance. But, because the data is biased, the performance estimates are too good or "overly optimistic" if they are calculated in the conventional way ("labeled outcomes only"). This is why they are proposing the contraction algorithm.
One of the concepts to denote when reading the Lakkaraju paper is the difference between the global goal of prediction and the goal in this specific setting. The global goal is to have a low failure rate with high acceptance rate, but at the moment we are not interested in it. The goal in this setting is to estimate the true failure rate of the model with unseen biased data. That is, given selectively labeled data and an arbitrary black-box model $\mathcal{B}$ we are interested in estimating the model's performance in the whole data set with all ground truth labels.
One of the concepts to denote when reading the Lakkaraju paper is the difference between the global goal of prediction and the goal in this specific setting. The global goal is to have a low failure rate with high acceptance rate, but at the moment we are not interested in it. The goal in this setting is to estimate the true failure rate of the model with unseen biased data. That is, given only selectively labeled data and an arbitrary black-box model $\mathcal{B}$ we are interested in estimating performance of model $\mathcal{B}$ in the whole data set with all ground truth labels.
\section{Data generation}
...
...
@@ -77,12 +80,13 @@ In the setting without unobservables Z, we first sample an acceptance rate r for
\STATE If subject belongs to the top $(1-r)\cdot100\%$ of observations assigned to a judge, set $T=0$ else set $T=1$.
\STATE Halve the data to training and test sets at random.
\STATE For both halves, set $Y=$ NA if decision is negative ($T=0$).
\RETURN labeled training data, full training data, labeled test data, full test data
\end{algorithmic}
\end{algorithm}
\subsection{With unobservables (see also algorithm \ref{alg:data_with_Z})}
In the setting with unobservables Z, we first sample an acceptance rate r for all $M=100$ judges uniformly from a half-open interval $[0.1; 0.9)$. Then we assign 500 unique subjects (50000 in total) for each of the judges randomly and simulate their features X, Z and W as i.i.d standard Gaussian random variables with zero mean and unit (1) variance. Then, probability for negative outcome is calculated as $$P(Y=0|X=x, Z=z, W=w)=\sigma(\beta_Xx+\beta_Zz+\beta_Ww)$$ where $\beta_X=\beta_Z =1$ and $\beta_W=0.2$. Next, value for result Y is set to 0 if $P(Y =0| X, Z, W)\geq0.5$ and 1 otherwise. The conditional probability for the negative decision is defined as $$P(T=0|X=x, Z=z)=\sigma(\beta_Xx+\beta_Zz)+\epsilon$$ where $\epsilon\sim N(0, 0.1)$. Next, the data is sorted for each judge by the probabilities $P(T=0|X, Z)$ in descending order. If the subject is in the top $(1-r)\cdot100\%$ of observations assigned to a judge, the decision variable T is set to zero and otherwise to one.
In the setting with unobservables Z, we first sample an acceptance rate r for all $M=100$ judges uniformly from a half-open interval $[0.1; 0.9)$. Then we assign 500 unique subjects (50000 in total) for each of the judges randomly and simulate their features X, Z and W as i.i.d standard Gaussian random variables with zero mean and unit (1) variance. Then, probability for negative outcome is calculated as $$P(Y=0|X=x, Z=z, W=w)=\sigma(\beta_Xx+\beta_Zz+\beta_Ww)$$ where $\beta_X=\beta_Z =1$ and $\beta_W=0.2$. Next, value for result Y is set to 0 if $P(Y =0| X, Z, W)\geq0.5$ and 1 otherwise. The conditional probability for the negative decision (T=0) is defined as $$P(T=0|X=x, Z=z)=\sigma(\beta_Xx+\beta_Zz)+\epsilon$$ where $\epsilon\sim N(0, 0.1)$. Next, the data is sorted for each judge by the probabilities $P(T=0|X, Z)$ in descending order. If the subject is in the top $(1-r)\cdot100\%$ of observations assigned to a judge, the decision variable T is set to zero and otherwise to one.
\begin{algorithm}[] % enter the algorithm environment
\caption{Create data with unobservables}% give the algorithm a caption
...
...
@@ -94,32 +98,34 @@ In the setting with unobservables Z, we first sample an acceptance rate r for al
\STATE Sample features X, Z and W for each $N_{total}$ observations from standard Gaussian independently.
\STATE Calculate $P(Y=0|X, Z, W)$ for each observation
\STATE Set Y to 0 if $P(Y =0| X, Z, W)\geq0.5$ and to 1 otherwise.
\STATE Calculate $P(T=0|X, Z)$ for each observation
\STATE Sort the data by (1) the judges' and (2) by probabilities $P(T=0|X, Z)$ in descending order.
\STATE\hskip3.0em $\rhd$ Now the most dangerous subjects for each of the judges are at the top.
\STATE If subject belongs to the top $(1-r)\cdot100\%$ of observations assigned to that judge, set $T=0$ else set $T=1$.
\STATE Halve the data to training and test sets at random.
\STATE For both halves, set $Y=$ NA if decision is negative ($T=0$).
\RETURN labeled training data, full training data, labeled test data, full test data
\end{algorithmic}
\end{algorithm}
\section{Plotting / "Performance comparison"}
\subsection{Model fitting}
\section{Model fitting}\label{sec:model_fitting}
The models that are being fitted are logistic regression models from scikit-learn package. The solver is set to lbfgs (as there is no closed-form solution) and intercept is estimated by default. The resulting LogisticRegression model object provides convenient functions for fitting the model and getting probabilities for class labels. Please see the documentation at \url{https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html} or ask me (RL) for more details.
NB: These models can not be fitted if the data includes missing values. Therefore listwise deletion is done in cases of missing data (whole record is discarded).
All of the algorithms 4--7 and the contraction algorithm are model agnostic. Lakkaraju says in their paper "We train logistic regression on this training set. We also experimented with other predictive models and observed similar behaviour."
\subsection{Curves}
NB: The sklearn's regression model can not be fitted if the data includes missing values. Therefore list-wise deletion is done in cases of missing data (whole record is discarded).
\section{Plotting}
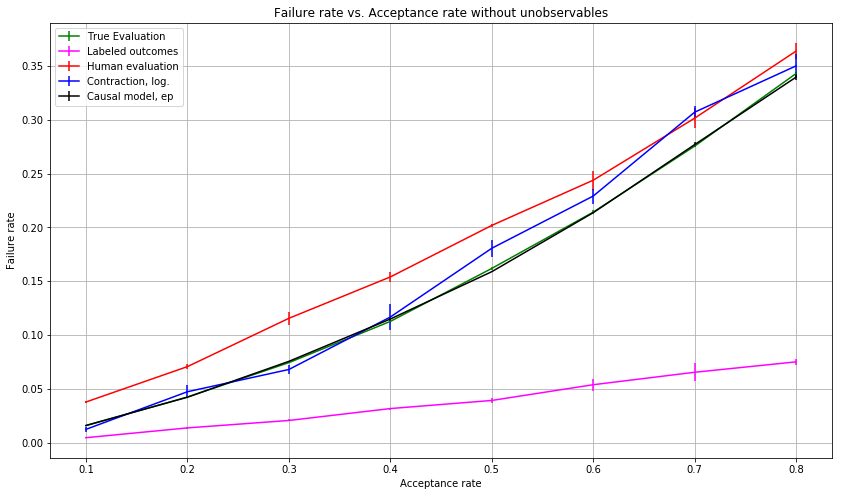
The following quantities are estimated from the data:
\begin{itemize}
\item True evaluation: The true failure rate of the model. Can only be calculated for synthetic data sets. See algorithm \ref{alg:true_eval}.
\item Labeled outcomes: The "traditional"/vanilla estimate of model performance. See algorithm \ref{alg:labeled_outcomes}.
\item Human evaluation: The failure rate of human decision-makers who have acces to the latent variable Z. Decision-makers with similar values of leniency are binned and trated as one hypothetical decision-maker. See algorithm \ref{alg:human_eval}.
\item Human evaluation: The failure rate of human decision-makers who have access to the latent variable Z. Decision-makers with similar values of leniency are binned and treated as one hypothetical decision-maker. See algorithm \ref{alg:human_eval}.
\item Contraction: See algorithm 1 of \cite{lakkaraju17}
\item Causal model: In essence, the empirical performance is calculated over the test set as $$\dfrac{1}{n}\sum_{(x, y)\in D}f(x)\delta(F(x) < r)$$ where $$f(x)= P(Y=0|T=1, X=x)$$ is a predictive model trained on the labeled data and $$ F(x_0)=\int P(x)\delta(f(x) < f(x_0)) ~ dx.$$ All observations, even ones with missing outcome labels, can be used since empirical performance doesn't depend on them. $P(x)$ is Gaussian pdf from scipy.stats package and it is integrated over interval [-15, 15] with 40000 steps using si.simps function from scipy.integrate which uses Simpson's rule in estimating the value of the integral. (docs: \url{https://docs.scipy.org/doc/scipy/reference/generated/scipy.integrate.simps.html}) \label{causal_cdf}
\item Causal model: In essence, the empirical performance is calculated over the test set as $$\dfrac{1}{n}\sum_{(x, y)\in D}f(x)\delta(F(x) < r)$$ where $$f(x)= P(Y=0|T=1, X=x)$$ is a logistic regression model (see \ref{sec:model_fitting}) trained on the labeled data and $$ F(x_0)=\int_{x\in\mathcal{X}} P(x)\delta(f(x) < f(x_0)) ~ dx.$$ All observations, even ones with missing outcome labels, can be used since empirical performance doesn't depend on them. $P(x)$ is Gaussian pdf from scipy.stats package and it is integrated over interval [-15, 15] with 40000 steps using si.simps function from scipy.integrate which uses Simpson's rule in estimating the value of the integral. (docs: \url{https://docs.scipy.org/doc/scipy/reference/generated/scipy.integrate.simps.html}) \label{causal_cdf}
\end{itemize}
The plotted curves are constructed using pseudo code presented in algorithm \ref{alg:perf_comp}.
...
...
@@ -134,18 +140,19 @@ The plotted curves are constructed using pseudo code presented in algorithm \ref
\FORALL{$r$ in $0.1, 0.2, ..., 0.9$}
\FOR{i = 1 \TO$N_{iter}$}
\STATE Create data using either Algorithm \ref{alg:data_without_Z} or \ref{alg:data_with_Z}.
\STATE Train a logistic regression model using observations in the training set with available outcome labels.
\STATE Estimate failure rate of true evaluation with leniency $r$ using algorithm \ref{alg:true_eval}.
\STATE Estimate failure rate of labeled outcomes approach with leniency $r$ using algorithm \ref{alg:labeled_outcomes}.
\STATE Estimate failure rate of human judges with leniency $r$ using algorithm \ref{alg:human_eval}.
\STATE Estimate failure rate of contraction algorithm with leniency $r$.
\STATE Estimate the empirical performance of the causal model with leniency $r$ using algorithm \ref{alg:causal_model}.
\STATE Train a logistic regression model using observations in the training set with available outcome labels and assign to $f$.
\STATE Using $f$, estimate probabilities $\mathcal{S}$ for Y=0 in both test sets (labeled and full) for all observations and attach them to the respective data sets.
\STATE Compute failure rate of true evaluation with leniency $r$ and full test data using algorithm \ref{alg:true_eval}.
\STATE Compute failure rate of labeled outcomes approach with leniency $r$ and labeled test data using algorithm \ref{alg:labeled_outcomes}.
\STATE Compute failure rate of human judges with leniency $r$ and labeled test data using algorithm \ref{alg:human_eval}.
\STATE Compute failure rate of contraction algorithm with leniency $r$ and labeled test data.
\STATE Compute the empirical performance of the causal model with leniency $r$, predictive model $f$ and labeled test data using algorithm \ref{alg:causal_model}.
\ENDFOR
\STATE Calculate mean of the failure rate over the iterations for each algorithm separately.
\STATE Calculate standard error of the mean over the iterations for each algorithm separately.
\STATE Calculate means of the failure rates for each value of leniency and for each algorithm separately.
\STATE Calculate standard error of the mean for each value of leniency and for each algorithm separately.
\ENDFOR
\STATE Plot the failure rates with given levels of leniency $r$.
\STATE Calculate absolute mean errors of each algorithm compared to the true evaluation.
\STATE Calculate absolute mean errors of each algorithm compared to true evaluation.
\end{algorithmic}
\end{algorithm}
...
...
@@ -166,7 +173,7 @@ The plotted curves are constructed using pseudo code presented in algorithm \ref
\caption{Labeled outcomes}% give the algorithm a caption
\label{alg:labeled_outcomes}% and a label for \ref{} commands later in the document
\begin{algorithmic}[1] % enter the algorithmic environment
\REQUIRE Labeled test data $\mathcal{D}$ with probabilities $\mathcal{S}$ and \emph{missing outcome labels} for observations with ($T=0$), acceptance rate r
\REQUIRE Labeled test data $\mathcal{D}$ with probabilities $\mathcal{S}$ and \emph{missing outcome labels} for observations with $T=0$, acceptance rate r
\ENSURE
\STATE Assign observations with observed outcomes to $\mathcal{D}_{observed}$.
\STATE Sort $\mathcal{D}_{observed}$ by the probabilities $\mathcal{S}$ to ascending order.
...
...
@@ -180,7 +187,7 @@ The plotted curves are constructed using pseudo code presented in algorithm \ref
\caption{Human evaluation}% give the algorithm a caption
\label{alg:human_eval}% and a label for \ref{} commands later in the document
\begin{algorithmic}[1] % enter the algorithmic environment
\REQUIRE Labeled test data $\mathcal{D}$ with probabilities $\mathcal{S}$ and \emph{missing outcome labels} for observations with ($T=0$), acceptance rate r
\REQUIRE Labeled test data $\mathcal{D}$ with probabilities $\mathcal{S}$ and \emph{missing outcome labels} for observations with $T=0$, acceptance rate r
\ENSURE
\STATE Assign judges with leniency in $[r-0.05, r+0.05]$ to $\mathcal{J}$
@@ -190,20 +197,20 @@ The plotted curves are constructed using pseudo code presented in algorithm \ref
\end{algorithm}
\begin{algorithm}[] % enter the algorithm environment
\caption{Causal model, empirical performance}% give the algorithm a caption
\caption{Causal model, empirical performance (ep)}% give the algorithm a caption
\label{alg:causal_model}% and a label for \ref{} commands later in the document
\begin{algorithmic}[1] % enter the algorithmic environment
\REQUIRE Labeled test data $\mathcal{D}$ with probabilities $\mathcal{S}$ and \emph{missing outcome labels} for observations with ($T=0$), predictive model f, acceptance rate r
\REQUIRE Labeled test data $\mathcal{D}$ with probabilities $\mathcal{S}$ and \emph{missing outcome labels} for observations with $T=0$, predictive model f, acceptance rate r
\ENSURE
\STATE Create boolean array $T_{causal}= cdf(\mathcal{D}, f) < r$. See "Causal model" in \ref{causal_cdf}.
\RETURN$\frac{1}{|\mathcal{D}|}\sum_{i=1}^{\mathcal{D}}\mathcal{S}\cdot T_{causal}$ which is equal to $\frac{1}{|\mathcal{D}|}\sum_{x\in\mathcal{D}} f(x)\delta(F(x) < r)$
\end{algorithmic}
\end{algorithm}
\section{What if...}
\section{Results}
\subsection{We assign$\beta_Z=0$?}
\subsection{If$\beta_Z=0$ when data is generated with unobservables.}
If we assign $\beta_Z=0$, almost all failure rates drop to zero in the interval 0.1, ..., 0.3 but the human evaluation failure rate. Figures are drawn in Figures \ref{fig:betaZ_1_5} and \ref{fig:betaZ_0}.
...
...
@@ -221,10 +228,19 @@ If we assign $\beta_Z=0$, almost all failure rates drop to zero in the interval
\caption{$\beta_Z=0$}
\label{fig:betaZ_0}
\end{subfigure}
\caption{Failure rate with varying levels of leniency and unobservables. Results from algorithm \ref{alg:perf_comp} with $N_{iter}=4$.}\label{fig:betaZ_comp}
\caption{Failure rate vs. acceptance rate with unobservables in the data. Logistic regression was trained on labeled training data. Results from algorithm \ref{alg:perf_comp} with $N_{iter}=4$. Data was generated with algorithm \ref{alg:data_with_Z}.}\label{fig:betaZ_comp}
\end{figure}
%\subsection{}
\subsection{If noise is added to the decision made when data is generated without unobservables}
Results are presented in Figure \ref{fig:sigma_figure}.

{kind=link}