
-
- Downloads
Kuvien päivitys, synt pois tekstistä, analyyseissä joitain muutoksia
Showing
- Kandi.pdf 0 additions, 0 deletionsKandi.pdf
- Kandi.synctex.gz 0 additions, 0 deletionsKandi.synctex.gz
- Kandi.tex 82 additions, 95 deletionsKandi.tex
- analysis_and_scripts/Bachelors_thesis_analyses.ipynb 1138 additions, 329 deletionsanalysis_and_scripts/Bachelors_thesis_analyses.ipynb
- analysis_and_scripts/Compas Analysis.ipynb 52 additions, 0 deletionsanalysis_and_scripts/Compas Analysis.ipynb
- analysis_and_scripts/tree.dot 573 additions, 0 deletionsanalysis_and_scripts/tree.dot
- analysis_and_scripts/tree.png 0 additions, 0 deletionsanalysis_and_scripts/tree.png
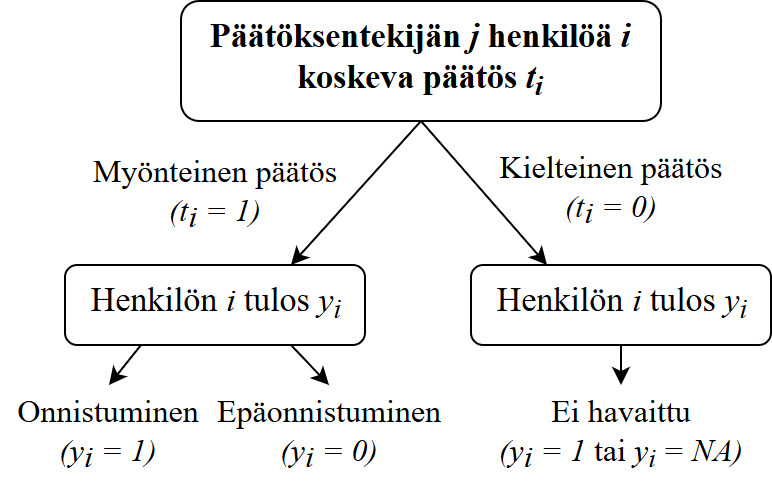
- figures/valikoitumis_iso.jpg 0 additions, 0 deletionsfigures/valikoitumis_iso.jpg
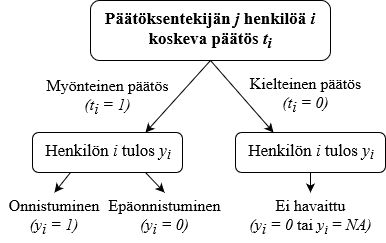
- figures/valikoitumisharha.png 0 additions, 0 deletionsfigures/valikoitumisharha.png
- figures/valikoitumisharha_kaaavio.drawio 1 addition, 0 deletionsfigures/valikoitumisharha_kaaavio.drawio
- viitteet.bib 8 additions, 0 deletionsviitteet.bib
No preview for this file type
No preview for this file type
This diff is collapsed.
This diff is collapsed.






analysis_and_scripts/tree.dot
0 → 100644
This diff is collapsed.
analysis_and_scripts/tree.png
0 → 100644
{kind=link}

1.83 MiB
figures/valikoitumis_iso.jpg
0 → 100644
{kind=link}
107 KiB
figures/valikoitumisharha.png
0 → 100644
{kind=link}
11.3 KiB
figures/valikoitumisharha_kaaavio.drawio
0 → 100644