%\newcommand{\ourtitle}{Working title: From would-have-beens to should-have-beens: Counterfactuals in model evaluation}
\newtheorem{problem}{Problem}
\newcommand{\ourtitle}{Evaluating Decision Makers over Selectively Labeled Data}
...
...
@@ -491,7 +489,7 @@ In this section we present our results from experiments with synthetic and reali
We experimented with synthetic data sets to examine accurateness, unbiasedness and robustness to violations of the assumptions.
We sampled $N=50k$ samples of $X$, $Z$, and $W$ as independent standard Gaussians. We then drew the outcome $Y$ from a Bernoulli distribution with parameter $p =1-\invlogit(\beta_xx+\beta_zz+\beta_ww)$ so that $P(Y=0|X, Z, W)=\invlogit(\beta_xx+\beta_zz+\beta_ww)$ where the coefficients for X, Z and W were set to $1$, $1$,$0.2$ respectively. We sampled leniency levels $R$ for each of the $M=100$ judges uniformly from $[0.1; 0.9]$. We assigned the subjects randomly such that a judge level was assigned for $500$ subjects. In the example, this mimics having 100 judges deciding each for $500$ defendants. The data was divided in half to form a training set and a test set. This process follows the suggestion of Lakkaraju et al. \cite{lakkaraju2017selective}. \acomment{Check before?}
We sampled $N=7k$ samples of $X$, $Z$, and $W$ as independent standard Gaussians. We then drew the outcome $Y$ from a Bernoulli distribution with parameter $p =1-\invlogit(\beta_xx+\beta_zz+\beta_ww)$ so that $P(Y=0|X, Z, W)=\invlogit(\beta_xx+\beta_zz+\beta_ww)$ where the coefficients for X, Z and W were set to $1$, $1$ and$0.2$ respectively. Then the leniency levels $R$ for each of the $M=14$ judges were assigned pairwise so that the judges had leniencies $0.1,~0.2,\ldots, 0.7$. The subjects were assigned randomly to the judges so each received $500$ subjects. The data was divided in half to form a training set and a test set. This process follows the suggestion of Lakkaraju et al. \cite{lakkaraju2017selective}. \acomment{Check before?}
The \emph{default} decision maker in the data predicts a subjects' probability for recidivism to be $P(\decision=0~|~\features, \unobservable)=\invlogit(\beta_xx+\beta_zz)$. Each of the decision-makers is assigned a leniency value, so the decision is then assigned by comparing the value of $P(\decision=0~|~\features, \unobservable)$ to the value of the inverse cumulative density function $F^{-1}_{P(\decision=0~|~\features, \unobservable)}(r)=F^{-1}(r)$. Now, if $F^{-1}(r) < P(\decision=0~|~\features, \unobservable)$ the subject is given a negative decision $\decision=0$ and a positive otherwise. \rcomment{Needs double checking.} This ensures that the decisions made are independent and stochastically converge to $r$. Then the outcomes for which the decision was negative, were set to $0$.
...
...
@@ -505,20 +503,30 @@ We treat the observations as independent and the still the leniency would be a g
\paragraph{Evaluators}
We deployed multiple evaluator modules to estimate the true failure rate of the decider module. The estimates should be close to the true evaluation evaluator modules estimates and the estimates will eventually be compared to the human evaluation curve.
\begin{itemize}
\begin{itemize}
\item\emph{True evaluation:} True evaluation depicts the true performance of a model. The estimate is computed by first sorting the subjects into a descending order based on the prediction of the model. Then the true failure rate estimate is computable directly from the outcome labels of the top $1-r\%$ of the subjects. True evaluation can only be computed on synthetic data sets as the ground truth labels are missing.
\item\emph{Human evaluation:} Human evaluation presents the performance of the decision-makers who observe the latent variable. Human evaluation curve is computed by binning the decision-makers with similar values of leniency into bins and then computing their failure rate from the ground truth labels. \rcomment{Not computing now.}
%\item \emph{Human evaluation:} Human evaluation presents the performance of the decision-makers who observe the latent variable. Human evaluation curve is computed by binning the decision-makers with similar values of leniency into bins and then computing their failure rate from the ground truth labels. \rcomment{Not computing now.}
\item\emph{Labeled outcomes:} Labeled outcomes algorithm is the conventional method of computing the failure rate. We proceed as in the true evaluation method but use only the available outcome labels to estimate the failure rate.
\item\emph{Contraction:} Contraction is an algorithm designed specifically to estimate the failure rate of a black-box predictive model under selective labeling. See previous section.
\end{itemize}
\end{itemize}
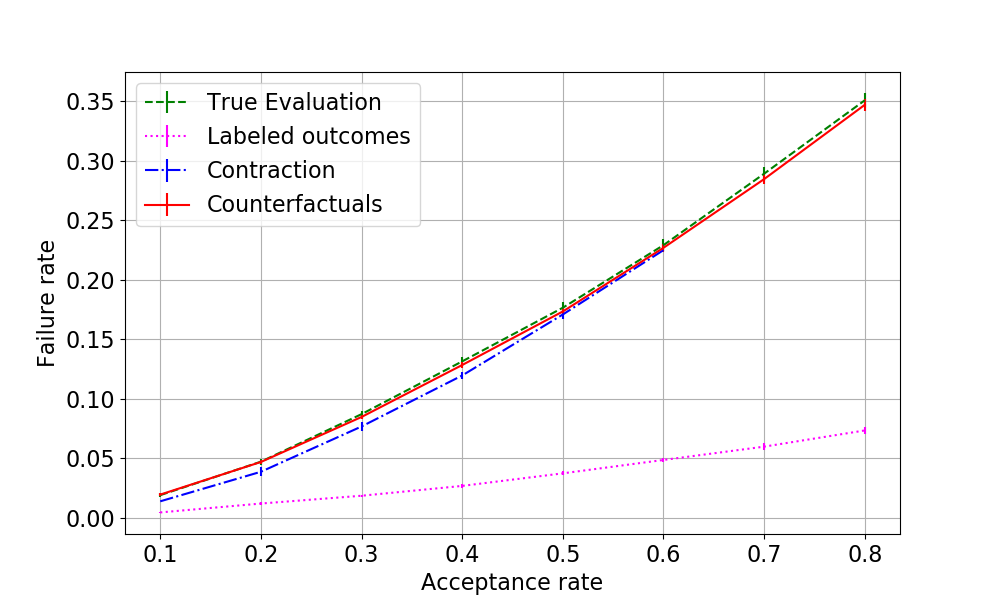
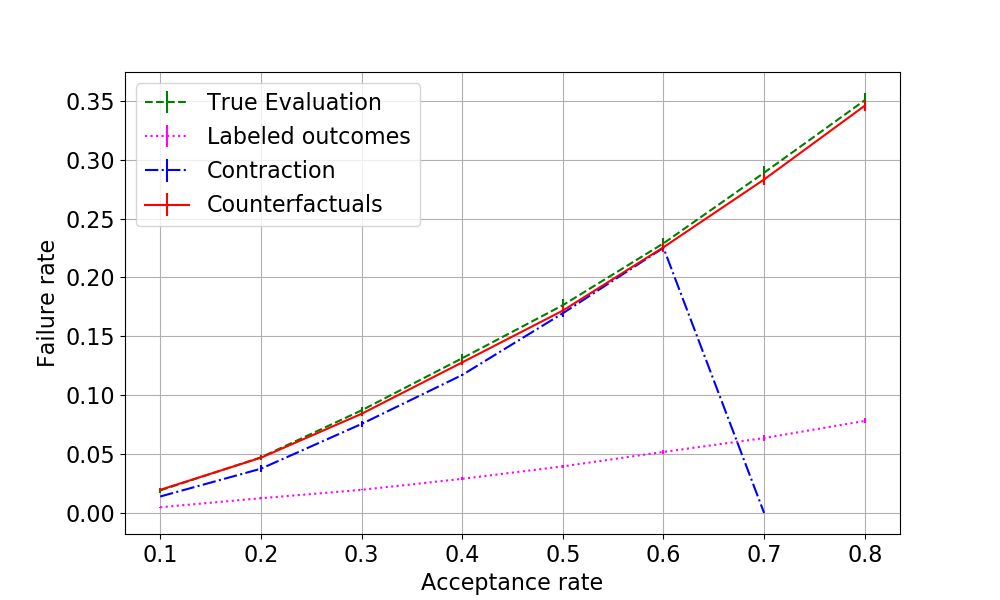
\paragraph{Results} We deployed the evaluators on the synthetic data set presented and the results are in Figure \ref{fig:results_main}. The new presented method can recover the true performance of a model for all levels of leniency. In the figure we see, how contraction algorithm can only estimate the true performance up to the level of the most lenient decision-maker. (The mean absolute errors on leniency levels from 0.1 to 0.6 were 0.007605 for contraction and 0.001912 for our method. Our error approximately $75\%$ smaller.)
\paragraph{Results}
(Target for this section from problem formulation: show that our evaluator is unbiased/accurate (show mean absolute error), robust to changes in data generation (some table perhaps, at least should discuss situations when the decisions are bad/biased/random = non-informative or misleading), also if the decider in the modelling step is bad and its information is used as input, what happens.)
\begin{itemize}
\item Accuracy: we have defined two metrics, acceptance rate and failure rate. In this section we show that our method can accurately restore the true failure on all acceptance rates with low mean absolute error. As figure X shows are method can recover the true performance of the predictive model with good accuracy. The mean absolute errors w.r.t the true evaluation were 0.XXX and 0.XXX for contraction and CBI approach respectively.
\item In figure X we also present how are method can track the true evaluation curve with a low variance.
\caption{Failure rate vs Acceptance rate with independent decisions -- comparison of the methods, error bars denote standard deviation of the estimate. Here we can see that the new proposed method (red) can recover the true failure rate more accurately than the contraction algorithm (blue). In addition, the new method can accurately track the \emph{true evaluation} curve (green) for all levels of leniency regardless of the leniency of the most lenient decision maker.}
\caption{Failure rate vs Acceptance rate with batch decisions -- comparison of the methods, error bars denote standard deviation of the estimate. Here we can see that the new proposed method (red) can recover the true failure rate more accurately than the contraction algorithm (blue). In addition, the new method can accurately track the \emph{true evaluation} curve for all levels of leniency regardless of the leniency of the most lenient decision maker. \rcomment{Contraction at 0.7 is a bug. Standard deviations are in the order $0.003$ so their bars are quite tiny.}}
\label{fig:results_main}
\end{figure}
\subsection{Realistic data}
In this section we present results from experiments with (realistic) data sets.

{kind=link}
{kind=link}