
Thesis related, multiple chapters finalized, references and figures added
Showing
- Kandi.tex 136 additions, 271 deletionsKandi.tex
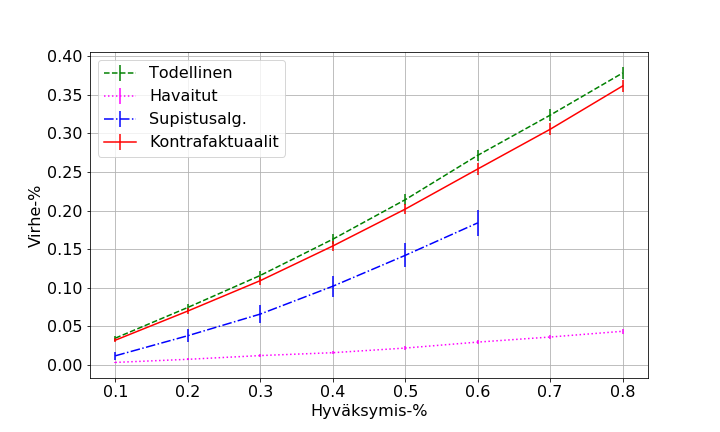
- figures/sl_thesis_bz5__all.png 0 additions, 0 deletionsfigures/sl_thesis_bz5__all.png
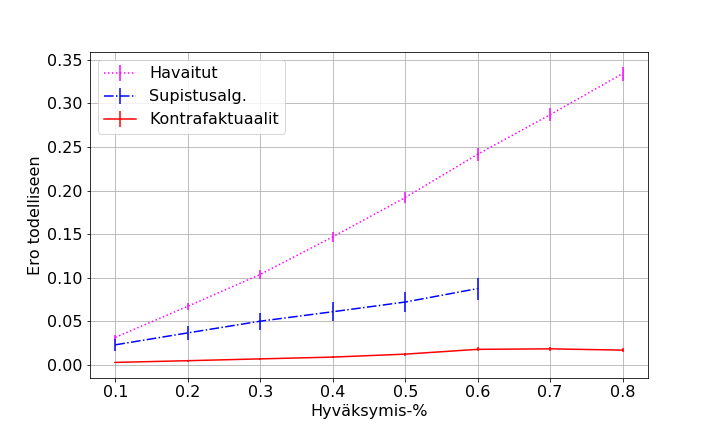
- figures/sl_thesis_bz5__all_err.png 0 additions, 0 deletionsfigures/sl_thesis_bz5__all_err.png
- figures/sl_thesis_loki_r_max_point_9.txt 36 additions, 0 deletionsfigures/sl_thesis_loki_r_max_point_9.txt
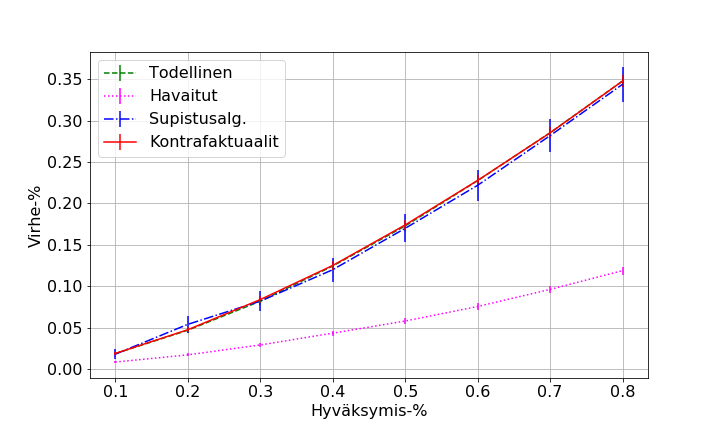
- figures/sl_thesis_r_max_point_9__all.png 0 additions, 0 deletionsfigures/sl_thesis_r_max_point_9__all.png
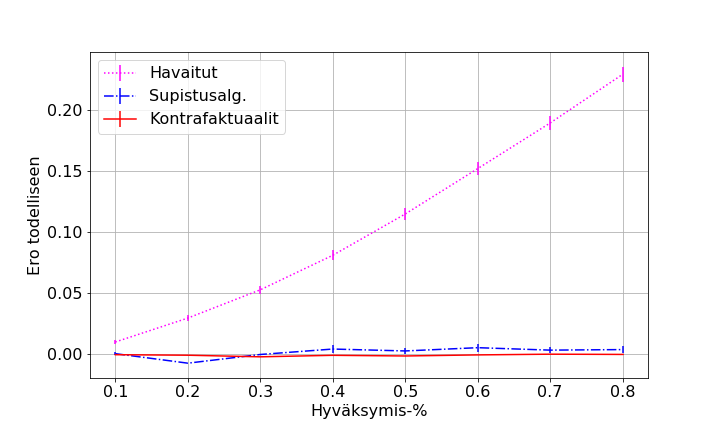
- figures/sl_thesis_r_max_point_9__all_err.png 0 additions, 0 deletionsfigures/sl_thesis_r_max_point_9__all_err.png
- viitteet.bib 45 additions, 3 deletionsviitteet.bib
figures/sl_thesis_bz5__all.png
0 → 100644
{kind=link}
43.9 KiB
figures/sl_thesis_bz5__all_err.png
0 → 100644
{kind=link}
31.4 KiB
figures/sl_thesis_loki_r_max_point_9.txt
0 → 100644
figures/sl_thesis_r_max_point_9__all.png
0 → 100644
{kind=link}
39.5 KiB
figures/sl_thesis_r_max_point_9__all_err.png
0 → 100644
{kind=link}
28.5 KiB