
-
- Downloads
First new figures, text
Showing
- analysis_and_scripts/notes.tex 18 additions, 19 deletionsanalysis_and_scripts/notes.tex
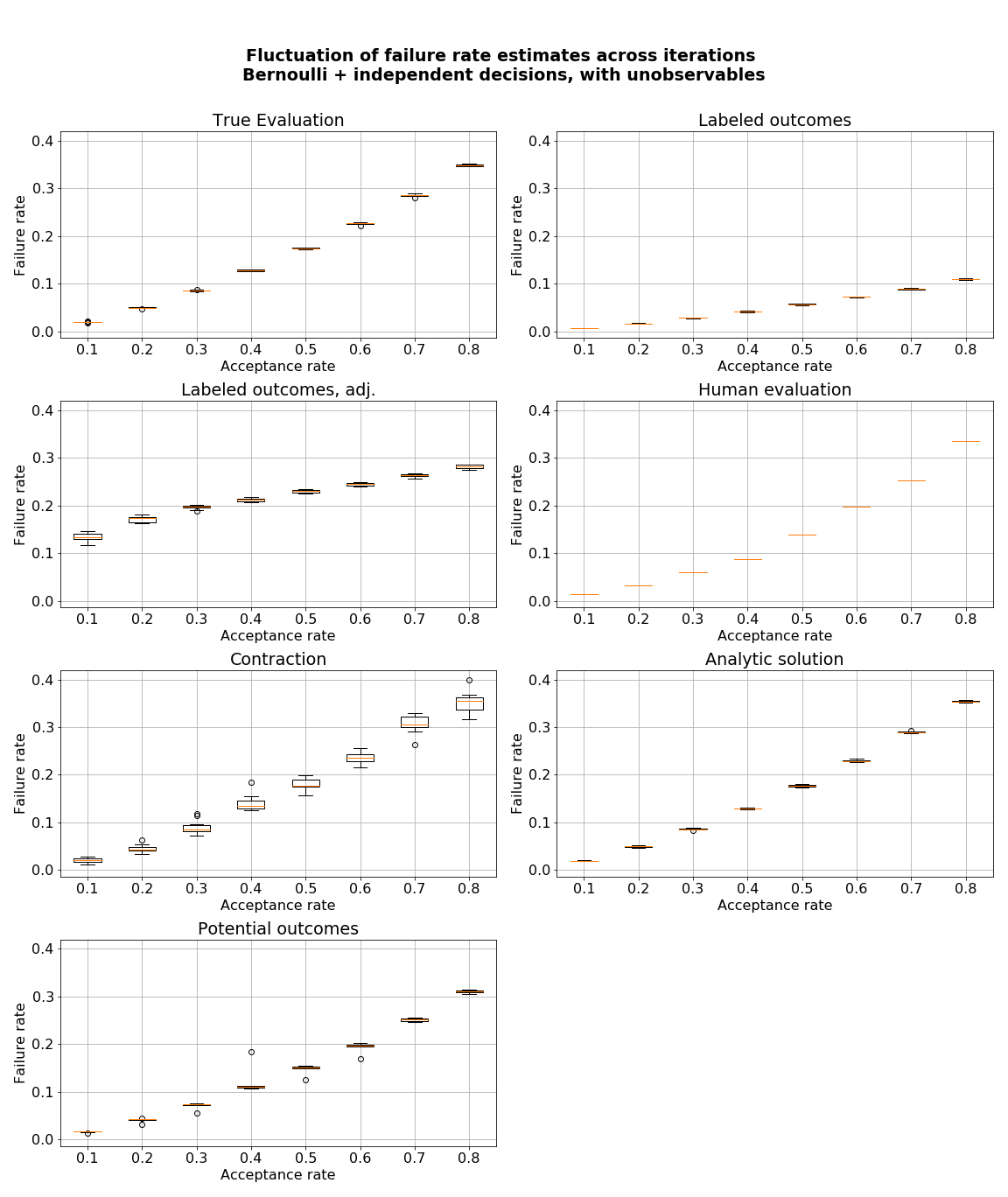
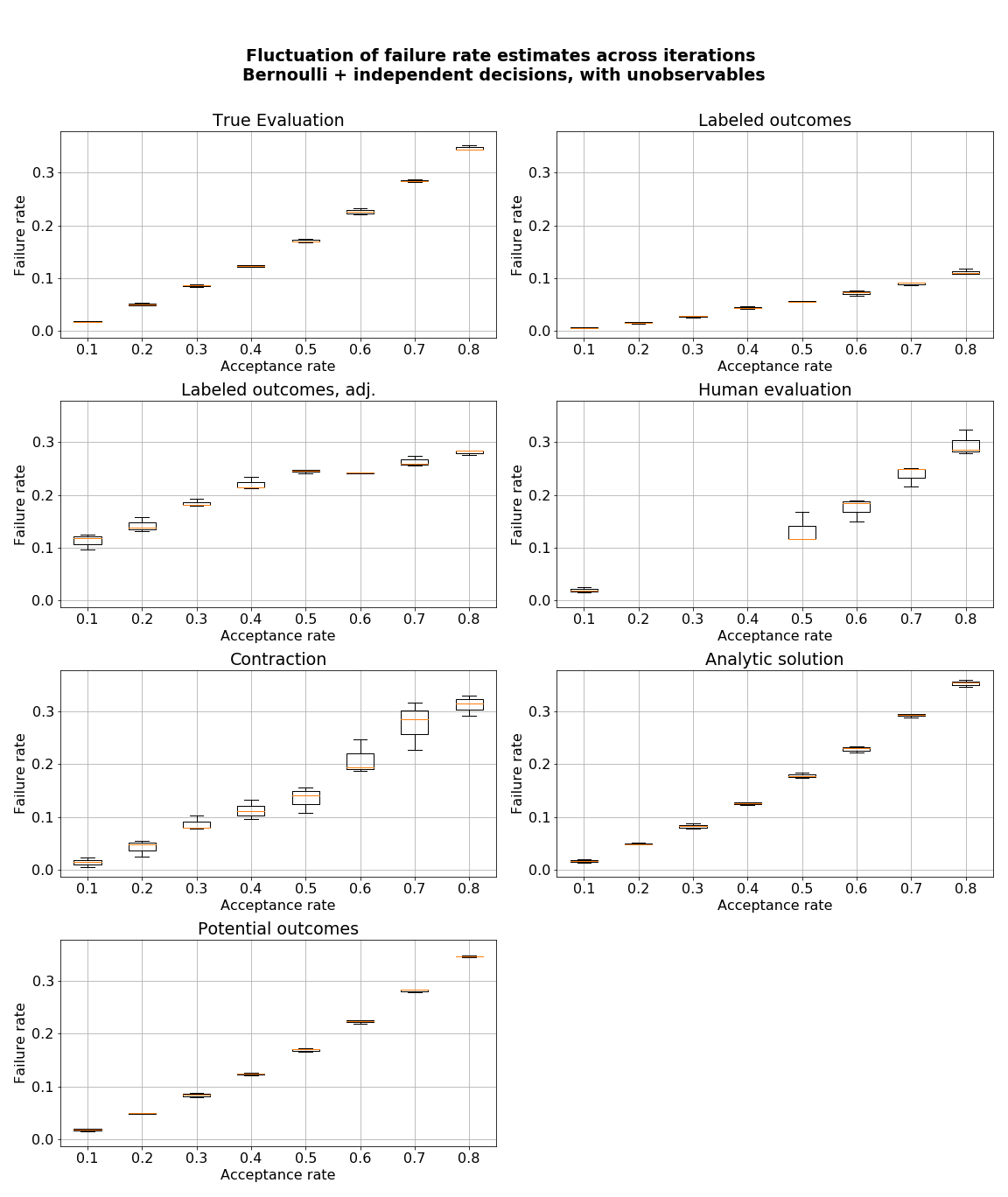
- figures/sl_diagnostic_bernoulli_independent_with_Z.png 0 additions, 0 deletionsfigures/sl_diagnostic_bernoulli_independent_with_Z.png
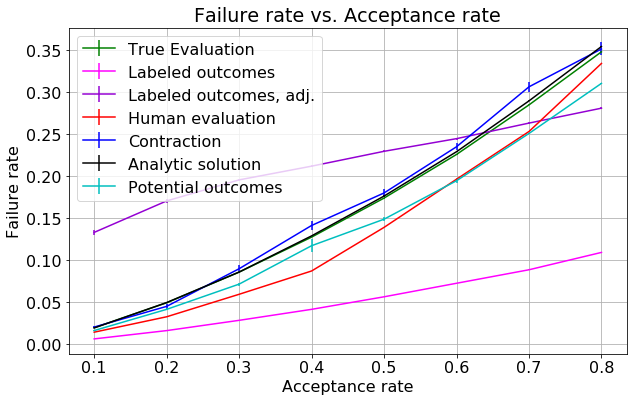
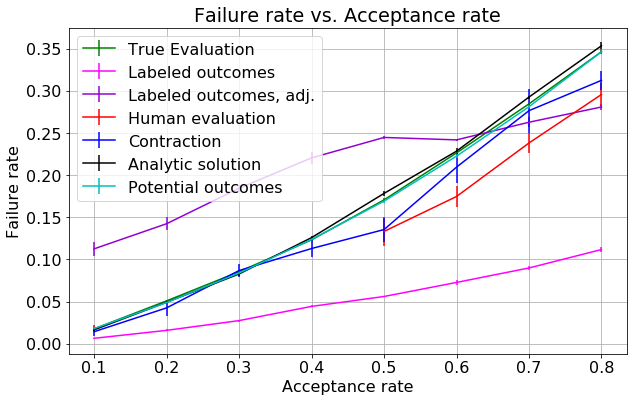
- figures/sl_result_bernoulli_independent.png 0 additions, 0 deletionsfigures/sl_result_bernoulli_independent.png
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H: